From Zero to DMP: implementing a localised instance of Data Stewardship Wizard

My name is Mouhamad Aboshokor, and I have been working as a data scientist and ML engineer for the past 8 years and currently, as a senior data scientist, I provide professional advice on data science, data management and AI procedures for the Digital Transformation Innovation Institute at Cardiff University.
Like many other research institutions, people at Cardiff University manage significant volumes of data. When I first assumed this role, one of the first activities I undertook was to meet with various data producers and consumers around the university, across multiple schools from medicine to engineering, with the aim of understanding the data landscape across the university and the way it was managed.
Despite the significant efforts and noticeable success of our researcher, after carrying out this exercise, I was left with an overwhelming sense of disunity. As different research groups had access to different facilities, collected different types of data, and targeted different funding streams, they organically developed different data management and stewardship strategies. Yet more importantly, there was a clear need for a centralised and streamlined process to review different data management plans, evaluate them easily against FAIR principles and share best practices across the compartmentalised boundaries of schools and research groups. Data Stewardship Wizard (DSW) presented an answer to address this need. Our aim from this piece is to share our experience with the deployment of local DSW instances to oversee Data Management Plans at Cardiff and the role we envision it to play in the larger data management strategy across the university.
Getting started
Deploying and customising DSW for your own institution requires understanding how the wizard defines and uses Knowledge Models, Document Templates, Questionnaires and documents, described at length in DSW User Guide and the Data Stewardship Wizard’s YouTube channel.
Using DSW begins with the creation of a Knowledge Model, which defines the structure and logic of data management planning. As a blueprint or question bank, it includes chapters, questions, and guidance. It can be built around the requirements of a specific funder, research domain, or project group. Conditional and scoring logic can be added to adapt the questionnaire dynamically and assess compliance with FAIR principles.
From this model, a Questionnaire is instantiated within a project. It serves as an interactive interface through which information is collected from data stewards building the DMP. The questions can change dynamically based on responses, and it supports collaborative input and review from multiple users.
To ensure that outputs meet formal requirements, a Document Template is applied. This template controls the formatting and structure of the final output/export, defining the logic to convert questions and answers in a project into a formal document and enabling compliance with funder guidelines or internal standards.
A document can be generated at any stage of the questionnaire using the selected template, reflecting the current responses in the project. A live preview is also available, automatically updating with each change, allowing users to review the plan in real time without downloading. These features support iterative refinement and ensure the final output is always up to date and ready for submission, evaluation, or archiving.
Through this process, structured, reusable, and standards-aligned data management planning is achieved.
Through coding new knowledge models, document templates and projects, an institution can define or customise DMP workflows, such as those from UKRI, enabling researchers to create and archive DMPs via a web interface using a series of questions, prompts and text boxes. Here’s the short, high-level YouTube pitch, though the resources that have helped me understand more about how to support its use before reading the DSW User Guide, have been a quick overview video of how a researcher would use DSW, and an ELIXIR-UK RDM club video from 2023 signposting terminology and ways to customise.
The DSW ecosystem
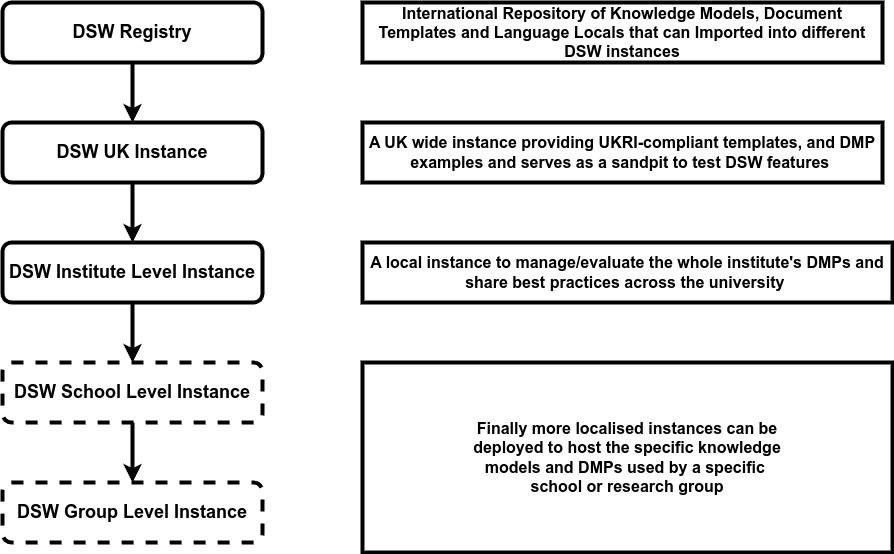
Figure 1: The DSW ecosystems from registry to institute level instance
From the start, we wanted the local instances to be a part of the larger DSW ecosystem, resulting in a hierarchical structure where best practices are shared easily without compromising information security (figure 1). The higher levels also serve as a sandbox for new converts to experiment with DSW features before taking the time and effort to implement it on the institute infrastructure and modify the local processes to incorporate it.
The DSW Registry
The DSW Registry serves as a central repository for sharing and accessing curated content across Data Stewardship Wizard instances. It provides a reliable way to download commonly used knowledge models, document templates, and locale configurations, supporting reuse and alignment with funder or disciplinary standards. Knowledge models and templates help standardise planning and documentation processes, while locales enable the adaptation of the DSW interface and content to different languages, enhancing accessibility for non-English-speaking users. This ensures that institutions and research groups do not need to build content from scratch, promoting consistency and efficiency and simplifying the sharing of best practices.
A local instance can import content from the registry, but can’t directly upload to it. The flow of information in the DSW Registry is intentionally one-way: local instances are designed to consume content rather than contribute directly to the central registry. Uploading or publishing new content is controlled by the DSW core team or authorised administrators, ensuring quality control, consistency, and alignment with shared standards.
Once a local instance is set up, accessing the registry involves linking it through the DSW administration interface, registering the instance, and using a generated token to connect. Once connected, content can be browsed and imported into the local instance, with version updates clearly indicated. Full instructions for accessing and using the registry can be found in the official DSW documentation.
A UK national Instance
The registry represents a transnational focal point for data stewardship content, which leads us to the next step in the hierarchy. ELIXIR hosts a national UK instance of DSW, currently without charge for UK research organisations, where we have used the space as a sandbox to learn the practicalities of using and coding DSW. Here we have created a BBSRC DMP template and used this to create and export 17 example DMPs as a proof of principle for this work.
Anyone can sign up to the instance. They will be automatically granted researcher role access, where they can create and access shared projects. Other roles, such as data steward and admin, can create templates, and grant new privileges shown in the table below (figure 2) and here.
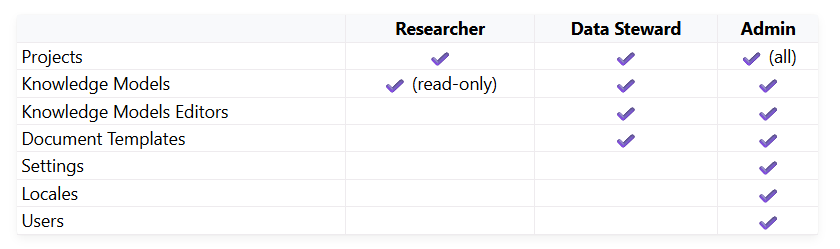
Figure 2: DSW permission level for administration and creation of DMPs
Our approach to hosting DSW locally
We tested different deployment routes from a technical standpoint to support the infrastructural requirements of different research groups and institutions. These routes require technical capabilities and are useful as a first test of a local DSW instance. When deploying a production instance, more care needs to be taken to handle secure proxies, backups and ensure the software updates are carried out regularly. For those scenarios, it is best to reach out to the DSW team early on to support you with your journey, especially if your technical skills are limited.
The simplest option, technically, is to use the official Docker Compose files provided by DSW, which come with very thorough documentation. This method is suitable for IT teams with access to dedicated servers or Virtual Machines (VMs), offering a straightforward and low-maintenance deployment path. It also facilitates smooth version updates by following DSW’s standard configuration.
For institutions using Kubernetes-based infrastructure, such as Red Hat OpenShift, a slightly more advanced approach is required. In this case, a continuous deployment (CD) pipeline can be built that utilises tools like Kompose.io, which converts Docker Compose files into Kubernetes service definitions. During our tests, we identified the need for minor modifications to the Docker files, including the addition of specific labels to ensure compatibility during the conversion. While this approach adds complexity and may complicate version updates, it brings benefits in terms of scalability, high availability, and better storage orchestration – key advantages of Kubernetes environments, especially when deployed at scale.
It is also possible to deploy DSW in cloud-native environments such as Microsoft Azure or Google Cloud Platform. This requires further customisation of the Docker configurations and potentially introduces additional challenges during DSW version upgrades. Although more complex, this option can integrate with cloud-native services and automated scaling, making it suitable for larger institutions or national research infrastructures.
In the case of Cardiff’s local instance, we opted for a slightly modified version of the basic Docker Compose deployment (figure 3). By using Red Hat OpenStack, we were able to allocate and manage local VMs efficiently. We applied institutional branding to the user interface and configured access restrictions to limit availability to users connected to the University’s VPN. This approach balanced ease of maintenance with strong internal security, avoiding the need for more complex authentication methods such as OpenID or two-factor authentication, though these are natively supported within DSW if needed.
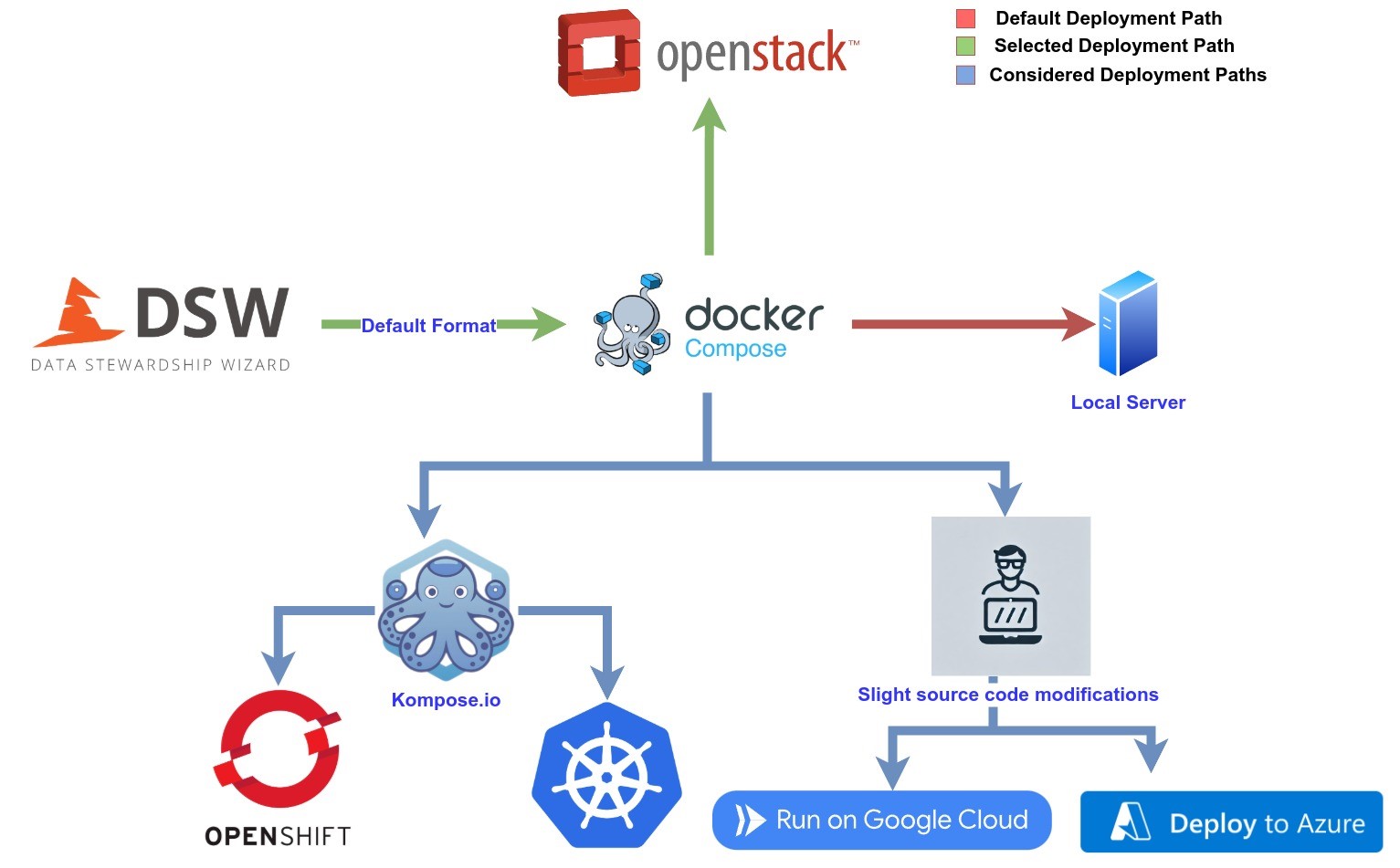
Figure 3: Methods for deploying DSW locally
Finally, DSW is offered by several service providers as a managed hosting option (SaaS) for institutions that prefer not to or cannot use local infrastructure. These include full deployment and configuration, and thus allow more focus on the content (knowledge model, document templates, project templates, etc.) without the need to deal with technical tasks. It is an ideal solution for teams without in-house technical expertise, ensuring that they can still benefit from the platform’s capabilities without handling the underlying infrastructure. Among the providers, ELIXIR (through ELIXIR-CZ) offers the open Researchers instance and dedicated instances for organisations affiliated with the ELIXIR network.
Easy customisations
One of the key strengths of the Data Stewardship Wizard (DSW) platform is its high degree of customisability. Throughout our deployment and configuration process, we were able to make several straightforward yet powerful adjustments to tailor the platform to our institutional context.
First, we customised the document export functionality by modifying the Jinja templates used in DSW’s document template engine. This allowed us to control exactly how content from the questionnaire was rendered into Word documents, including the insertion of structured tables, conditional sections, and institution-specific phrasing. DSW provides full documentation and examples for working with Jinja templates.
Second, we changed the look and feel of the user interface to reflect Cardiff University branding. This included uploading a custom logo, changing the colour scheme, and modifying the instance’s title and landing page. These changes are easily configurable through the DSW admin interface. The following page specifies the attributes to be modified to change the general look and feel and to modify the landing web page.
In addition to interface and template customisation, we also imported our own institution-specific knowledge models and document templates, and added modifications to them following the documentation. These were tailored to reflect local data management workflows and funder-specific requirements, providing a more relevant and guided experience for our researchers.
All of these customisations required only basic familiarity with HTML, Markdown, and YAML formats, and most changes were implemented through the DSW web interface or simple configuration files. While no code repository was necessary, examples of our Jinja logic for conditional section rendering and styling can be shared upon request, but a very good guide to the template customisation with Jinja can be found in this video tutorial on the DSW Development kit.
These adaptations demonstrate that even without extensive technical expertise, DSW can be effectively tailored to meet local needs, significantly improving user experience and alignment with institutional processes.
DSW meets GenAI
As part of Cardiff University’s ongoing effort to improve data stewardship practices and grant capture processes, we ran a short pilot project on the integration of Large Language Models (LLMs) with DSW. This initiative is grounded in our broader goal of centralising past grant applications and leveraging intelligent systems to streamline Data Management Plan (DMP) development. The pilot builds on the institution’s local deployment of DSW, which already supports institution-specific knowledge models, templates, and branding, offering a strong foundation for further automation and AI integration.
The proposed approach involves deploying a secure, locally hosted service where academic staff can upload past or current grant applications (figure 4). After uploading a document, users select a relevant funder-specific template and knowledge model within DSW. The LLM, also deployed locally, then scans the grant text to identify existing DMP content. Using a Retrieval-Augmented Generation (RAG) pipeline, the LLM retrieves relevant information from the uploaded text and maps it onto the corresponding fields of the selected DSW knowledge model, automatically pre-filling a new project. Researchers can then review, edit, and validate the content, which reduces the manual burden and helps highlight areas where additional details or improvements are needed.
This system supports standardisation across departments and research groups, ensuring that all DMPs adhere to institutional best practices and funder requirements. Moreover, the use of FAIR metrics embedded in DSW allows for automated scoring of the resulting plans. With minimal configuration, the platform can flag missing information or suggest revisions that would improve compliance with FAIR principles, making it easier for researchers to enhance the quality and competitiveness of their applications.
Beyond its immediate benefits, the larger aim of this pilot is to push towards the creation of a central, institutionally managed repository of grant applications. With user consent, uploaded documents can be archived and later used to train and fine-tune the local LLM. This growing dataset can also serve as a basis for institutional research into funding trends, common weaknesses in applications, and opportunities for targeted support and training. The following diagram illustrates the envisioned system.
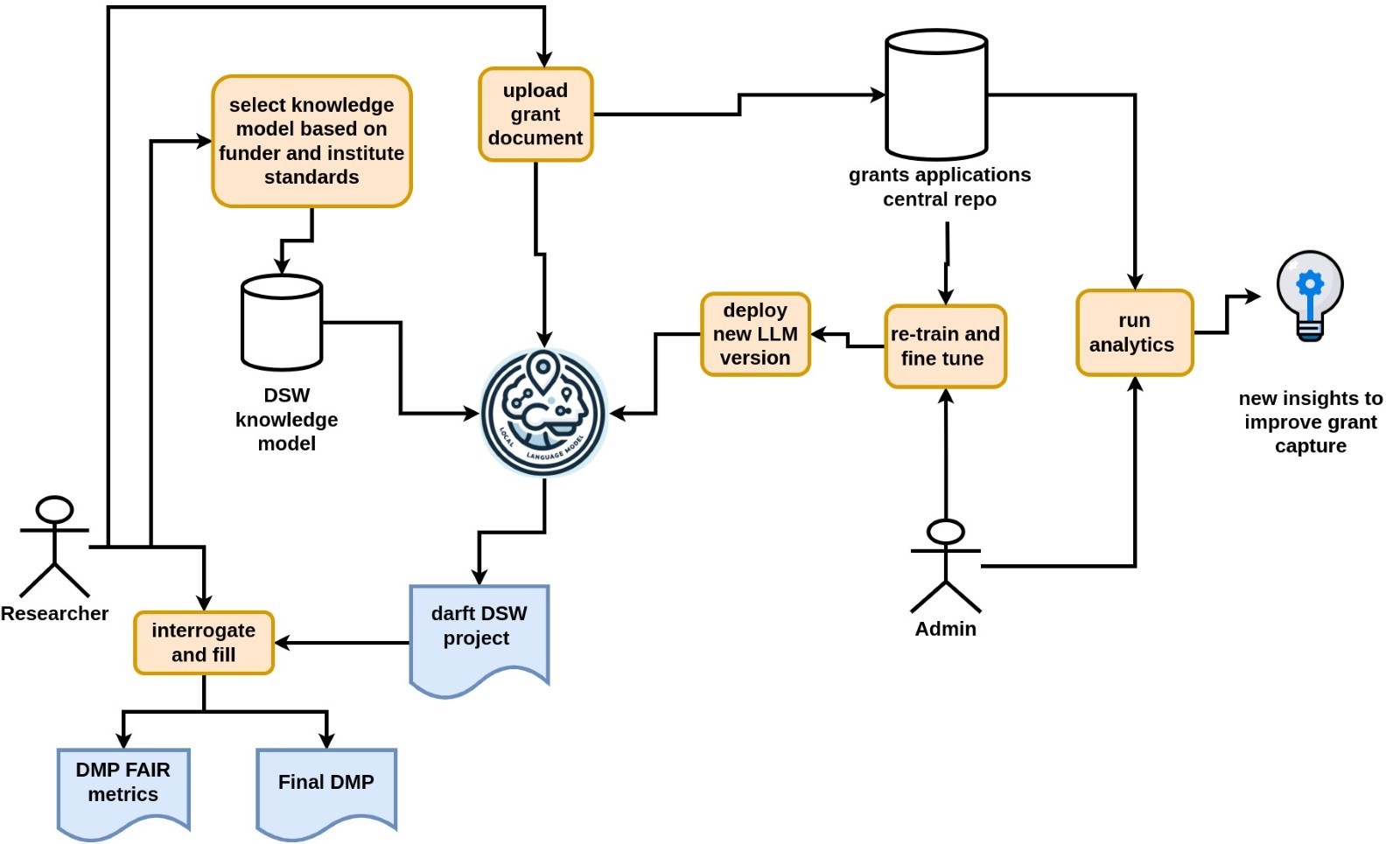
Figure 4: Flow chart of the envisioned system workflow
In the early stages of the pilot, significant effort was dedicated to building our local LLM pipeline and integrating it with the DSW API, enabling us to dynamically interrogate the knowledge model and construct a RAG pipeline capable of mapping input text to specific questionnaire items. For initial tests, we exported DMPs generated through our local DSW deployment as PDF files and used them as input examples. Various LLMs were evaluated for their ability to pre-fill new DSW projects based on this content. Specifically, we tested Gemma 3 12B using both SFP8 and Q4_0 quantisation, Mistral-Instruct-7B with Q4 quantisation, and Mixtral-8×7 B-Instruct. These models were chosen to balance performance and computational efficiency in a local deployment setting. Although we aimed to test more diverse DMPs to explore the impact of structure and style, initial findings were promising. Models with more than 7 billion parameters consistently demonstrated adequate performance, though some manual adjustment of generated answers was occasionally required to align them with DSW expectations.
These early tests were primarily focused on evaluating how easily applications can be built around the DSW API and how adaptable the system is for automation workflows. The DSW API proved to be simple, consistent, and well-documented. We even experimented with building a unified project importer using DSW Integration SDK to support the development. These qualities make DSW highly suitable for building lightweight plug-ins or intelligent assistants, demonstrating that it can serve not only as a planning tool but also as an integration-ready backend for more advanced data stewardship services.
Future work will shift toward a more rigorous assessment of LLM performance across a diverse set of DMPs drawn from various funders, disciplines, and document formats. This will include systematically comparing prompting strategies, assessing model sensitivity to document structure and language, and evaluating the effectiveness of different LLM architectures in accurately mapping content to DSW knowledge models. We plan to run controlled experiments using synthetic and anonymised DMP datasets to better quantify LLM coverage, accuracy, and alignment with institutional and FAIR principles. These evaluations will inform the development of robust, reproducible workflows for AI-assisted data stewardship and help identify optimal configurations for deployment within Cardiff University’s infrastructure.
By combining DSW’s structured and auditable planning environment with the generative and contextual strengths of LLMs, this pilot offers a scalable path toward enhancing Cardiff University’s research support infrastructure. It also sets the groundwork for broader institutional innovation around responsible AI adoption in higher education.
Final Thoughts
Our experience deploying and customising the Data Stewardship Wizard (DSW) was greatly supported by the strength of its documentation and the responsiveness of its community. The official guidance was thorough and reliable, and when we encountered more specific challenges, the Discord community – especially the core team – was quick to offer practical help.
This write-up aimed to provide a transparent view of the decisions, trade-offs, and technical steps we took. We hope it proves useful to others navigating similar deployments and encourages continued knowledge sharing across the DSW user base.