Customising Data Stewardship Wizard for an Institute

During my time at Rothamsted, I’ve reviewed a lot of Data Management Plans (DMPs). Some have been very good, but others miss the mark. I’ve become used to seeing DMPs with FAIR as a buzzword, but then no detail on how the project achieves FAIR data. All too often, I think Data Management Plans (DMPs) are viewed by researchers as another piece of grant writing admin, and whether the grant is awarded, the fate of the DMP is the same, filed away never to be looked at again.
I think there are several reasons for this. PIs are not taught how to write, value and use a DMP. Funders provide guidance on writing DMPs, but let’s be honest, I suspect it is only Data Management nerds like me who read it, read it again and then reference back to it!
Training can certainly help PIs write better DMPs, but so can access to DMP writing tools. A good DMP tool should guide a PI through the funders’ requirements.
But are most funder DMPs really that useful? A 500-word limit to describe all the data activities across a three-year project? Possibly not, especially if their primary purpose is for supporting a grant application, they can be pitched at too high a level for practical data management during a project. But, if they are seen as a starting point, they could become a living document which asks the useful questions for managing the data during the project life-cycle.
So a good DMP tool shouldn’t just guide the PI through the funder’s requirements, but also support PIs to meet their institution’s data and research integrity policies.
Given these challenges – unclear expectations, inconsistent templates, and limited engagement with DMPs – it’s clear that researchers need more than just guidance documents. They need tools that not only simplify the process but also embed good data management practices into the research lifecycle. This is where the Data Stewardship Wizard (DSW) comes in. As an open-source, customizable platform, DSW offers a structured yet flexible approach to creating meaningful, actionable DMPs that can evolve with a project. As part of a BBSRC-funded project with Cardiff University, I have been exploring how we might apply DSW to improve data management culture at a research institute
DSW has three components: Knowledge Models, Document templates and Projects.
Knowledge Models (KM) provide the structured framework that defines the questions, sections, and logic used to build a DMP questionnaire. A KM is therefore a schema for what information should be collected, when it should be collected, and how it should be organized.
Templates describe how the responses to a DMP questionnaire are composed into a document. This could provide us with a lot of flexibility to use a single DMP to generate multiple documents.
Projects are created by Researchers and this is where DMPs are created using questionnaires built from a Knowledge Model and export them as documents using Templates.
Managing the DMP Multiverse
Our researchers apply for grants from multiple different funders, and they all have different DMP guidelines and templates, and some don’t even require one. Our main funder, BBSRC, even has different guidance depending on the call, from short 500-word documents referencing UKRIs basic DMP guidance to detailed and structured templates.Over the last few years, we have also seen funders make explicit requirements to go FAIR and this should be communicated in the DMP.
None of this helps our researchers who are left bewildered by this DMP Multiverse. What detail really needs to go in the DMP, and how do we meet expectations for FAIR data, especially when many researchers still don’t fully understand what that means.
As part of our grants process we have introduced a step for researchers to identify and cost data management requirements. This step includes an optional DMP review to improve the DMP, but this offer is not always taken, especially on collaborative proposals where another organisation is the lead and therefore has responsibility for drafting the DMP. The downside to this as an institute is we lose oversight of DMPs being submitted, and their quality can vary across submissions, although how well DMPs are assessed is not obvious so the importance of DMP quality at the grant winning stage is not clear.
Another way we have tried to tackle this is through training. DMPs are covered as part of our institute Research Data Management training, though not in the detail our PIs might want. One reason we don’t go into too much detail is unless you practice what has been taught routinely, that learned knowledge is soon forgotten.
A third option is to provide a DMP authoring tool, and that’s what we’re hoping DSW can provide. For a research institute DSW provides some immediate benefits. DSW provides two very useful tools for creating and managing DMPs, the Knowledge Model and Document Templates. to customise the questions we ask, we can then use Document Templates to customise the output, for example by providing different funder templates to export content based on their requirements.
The Knowledge Model
DSW’s Knowledge Model (KM) allows us to design customisable DMP questionnaires using an intuitive web editor. You can build models from scratch, fork an existing model to refine it, or import a model from the DSW Registry.
A model will have at least one chapter and multiple questions. A chapter is used to group one or more related questions and is a useful tool for logically organising your questions.
Plan how you want the Knowledge Model to work
For our institute’s DMP, I want each project’s DMP to become a living document which is maintained throughout the project. This means at different time points I will want to ask the PI for different bits of information. For example, at the pre-award stage I might just want to align with the funder’s basic DMP requirements, but if the proposal is funded, I might want to capture more detail on the planned data deliverables, relevant data protocols, research notebooks, and data storage locations.
The model provides two useful features called Phases and Question Tags to help with this. Using Phases, I can specify when questions should be asked, for example, pre or post-award. Using Question Tags, I can tag related questions based on some common purpose, for example, I can tag pre-award phase questions as being relevant to either Horizon or UKRI DMP template, then use this as a criteria in later document template creation.
Thinking about how I want to use the data collected using Question Tags and when I want to collect data using Phases are important first steps in planning my Knowledge Model, and I would recommend doing this first. Of course, if I get it wrong the first time (and I usually do!) I can easily create a new KM version and make my corrections there, and following good practice, record my edits in the version change log.
Phases and Question Tags are added from the KM Root page (figure 1)

Figure 1: The DSW web interface for editing the knowledge model
Creating the KM
Once I have defined my Phases, Question Tags and Chapters I can start adding questions to my KM Chapters. If you’ve used online form builders before, DSWs KM editor should be familiar (figure 2.). It collects standard information such as the question type (text, list, multiple choice, file, integration, etc), a question title, and context sensitive help. We can also provide response validation rules such as Regex, min/max length and ORCID or DOI requirements, and ask follow-on questions depending on the response received.
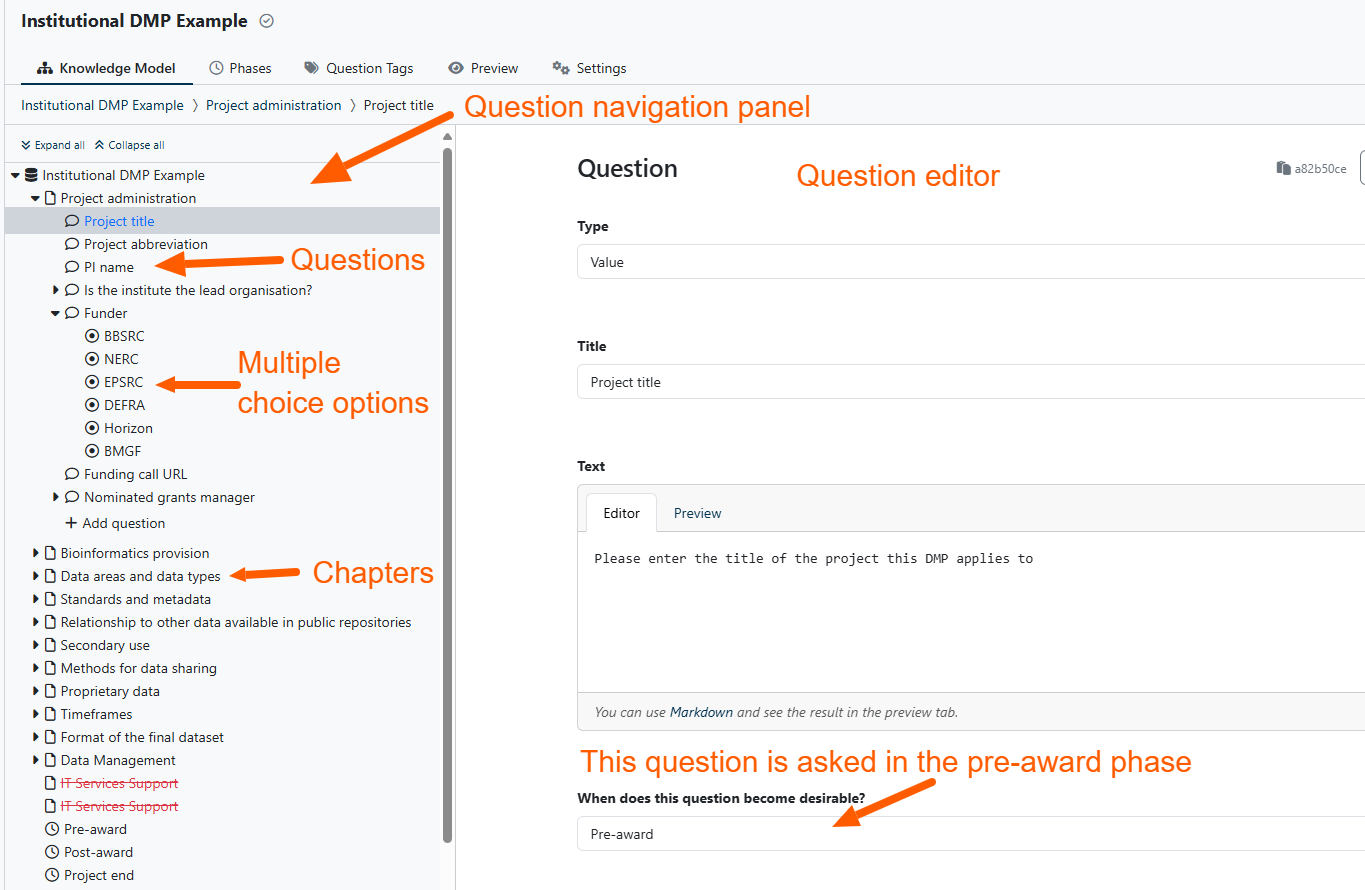
Figure 2. The DSW question editor
The question editor also provides more advanced features for enriching our DMP questionnaire. One of the more powerful is the Integrations. Using an Integration question I can query an external API for questions. For example, instead of a predefined funder options I can query the ROR API to obtain a list of funders, or use the FAIRSharing API to help identify relevant repositories or data standards.
Using Phases and Question Tags tabs I can easily see which questions are used and when (figure 3)
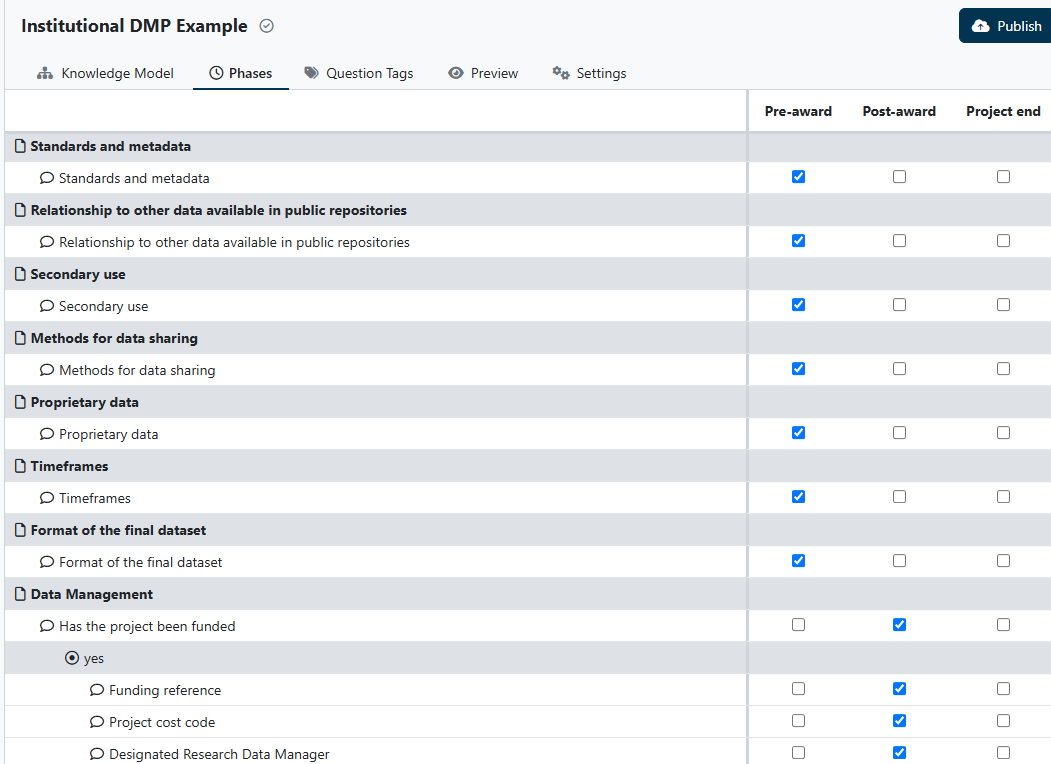
Figure 3. Matrix view of questions and phases used.
Once my KM is complete I can publish it and make it available to my researchers to start using (figure 4). Researchers can see which questions are required for each phase and can even add comments to questions.
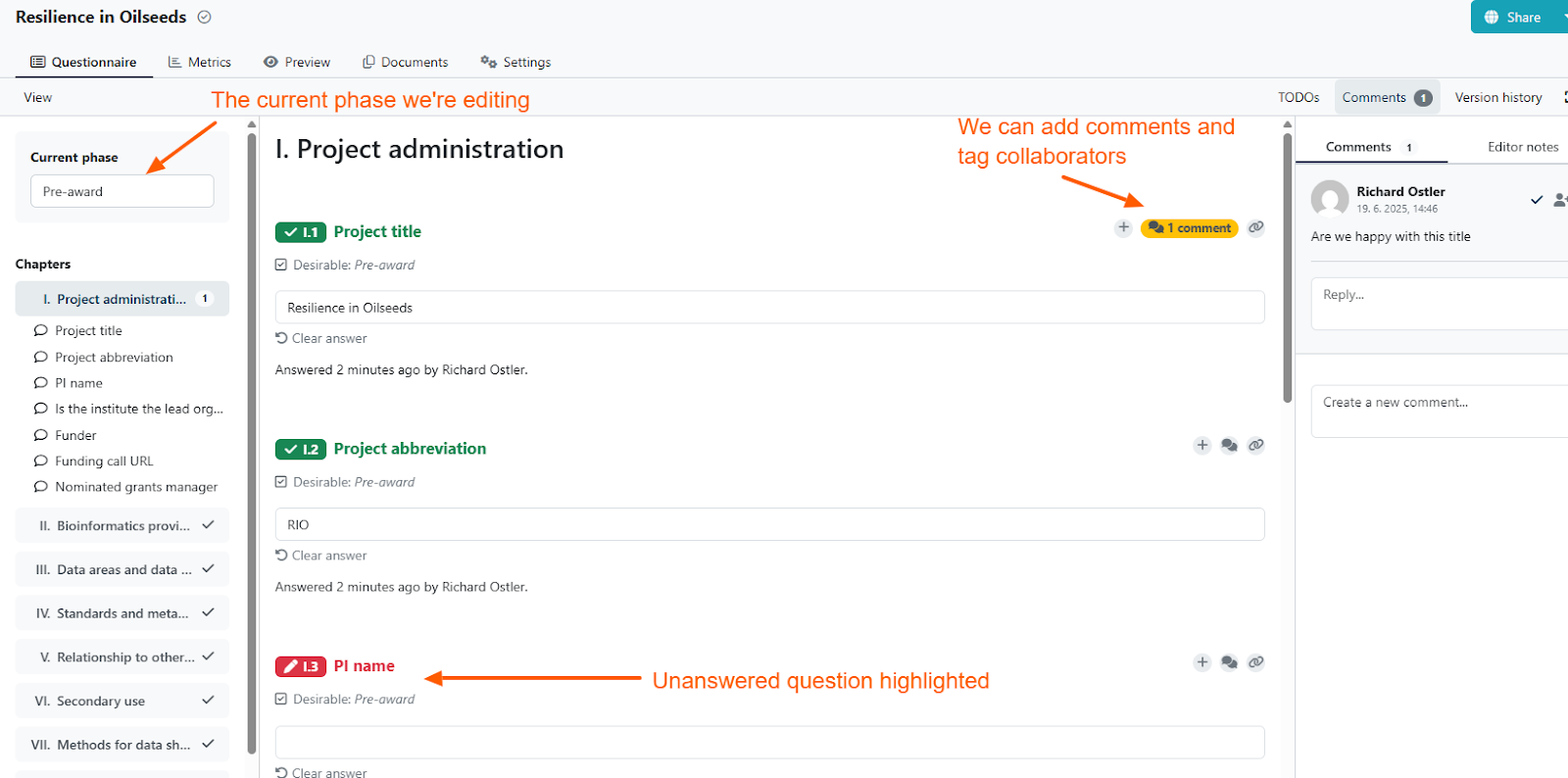
Figure 4. DSW Questionnaire
Templates
Now we have a working KM, and researchers can start writing DMPs, we next need a way for our researchers to export information as usable content. This is where document templates come in.
The DSW team provides a number of ready made templates in the DSW Registry, including for Machine Actionable DMPs. For me, Templates are where DSW gets a bit harder as you need to start using CSS and the Jinja templating language (figure 5.), so having some examples to start from is great. In fact this was my first time using Jinja and I found the language fairly straightforward and the help useful (full disclaimer I have spent some time as a software engineer).
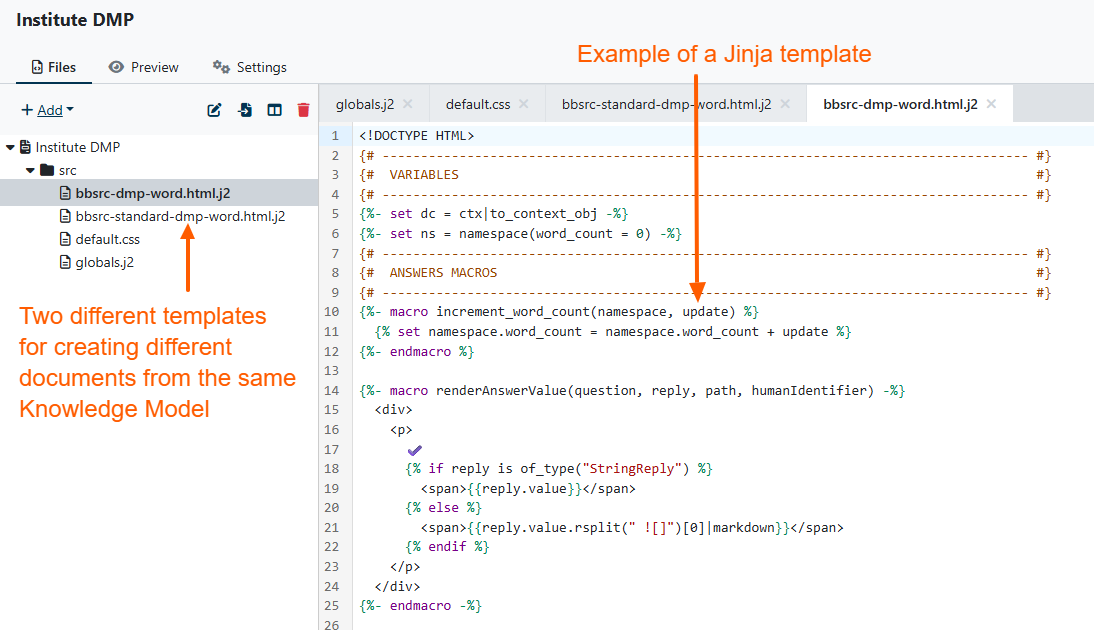
Figure 5. DSW Template editor
While using Jinja obviously has a learning curve and skill overhead, once you’ve mastered it you have great flexibility for customising the content and display of output documents. You can even create simple functions to perform tasks like word counts – useful if your funder has a word limit.
So what are the benefits of DSW for Research Institutes
So far we have been exploring DSW and what it can offer. We haven’t yet rolled DSW out to our researchers, but already we can see potential benefits, especially for helping to change culture around data management.
Funder DMP templates aren’t always that useful, and writing a detailed DMP at the proposal stage is both a lot of effort and probably not necessary. What I really want is a DMP template that is going to work for both the PI, their team and the data steward team. Part of that requirement is generating the relevant content for the funder, but the more important and useful part is using DSW to put the DMP at the heart of a funded project’s management. Customisable questions and phases allow us to do that. For example, we can use DSW first to define the planned data deliverables for a project post-award then update the status of these during the course of the project.
This benefits the institute because we now have a mechanism for easily reviewing progress across projects. By being clever in our choice of questions we can guide and encourage researchers to think about their data and plan ahead for how and when that data will be published and shared.
The benefits to PIs and project teams is they have a more rounded and usable tool for planning their data management, both at the grant writing stage and as a living document during the project. We can further tailor Knowledge Models to specific types of experiment or data type to provide more in depth guidance on metadata, formats and repositories to help researchers improve the FAIRness of different data types.
Finally, why stop at data? The beauty of a customisable tool is that we can repurpose for other use cases such as Software Management Plans, Sample Management Plans or Statistical Management Plans… we’ll just need a more imaginative set of abbreviations!